You are viewing the RapidMiner Hub documentation for version 10.2 - Check here for latest version
Create a process
The process that you will expose via an endpoint URL lives within a project. During development, you would normally configure the endpoint so that every time the project is updated, the associated endpoints also are updated -- automatically.
Consider, for example, the project test-1030-beta2, whose purpose is to identify
the type of Iris via the length and width of its sepals and petals.
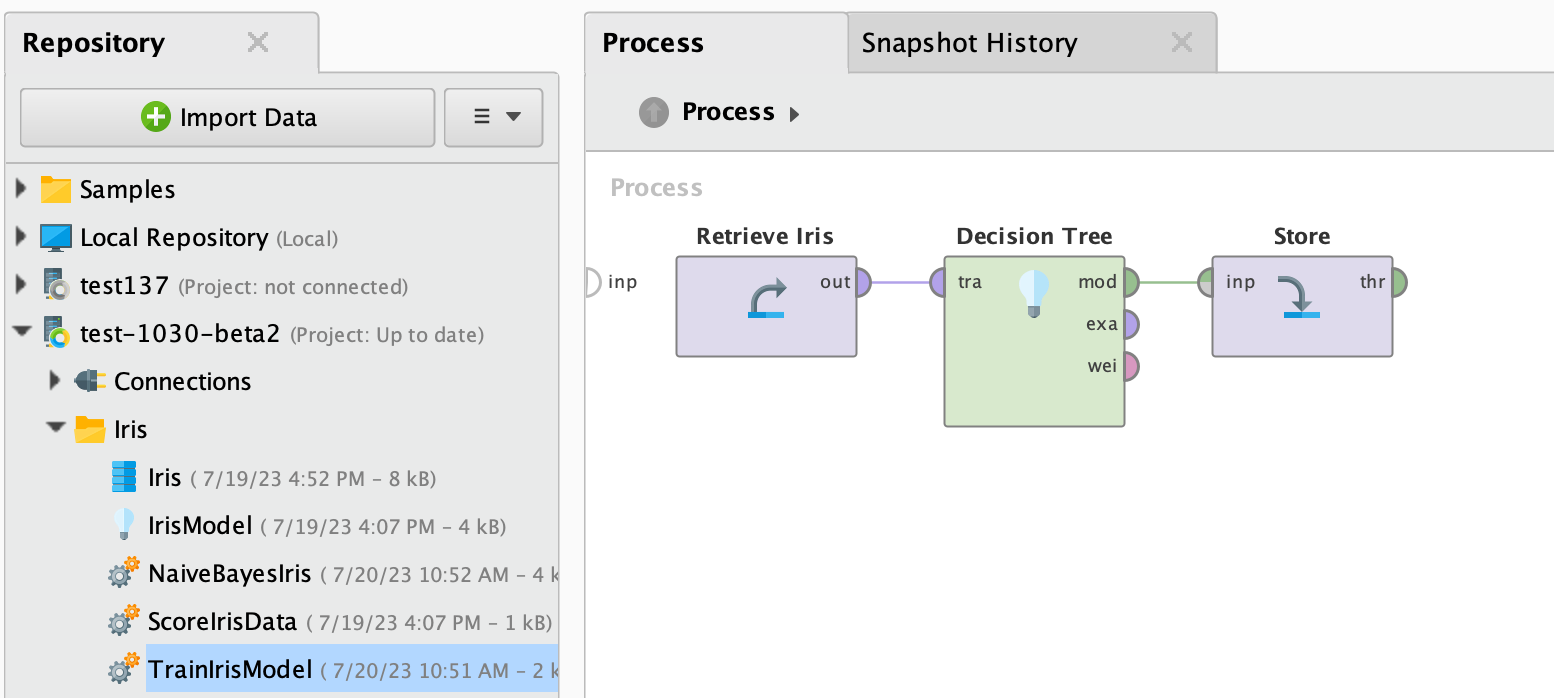
Within this project, the Iris folder has five components: 3 processes, one
model, and one data set. One of the processes, TrainIrisModel, is used to
train a Decision Tree model named IrisModel based on the Iris data set:
While in this case model training is quick, normally you would not include model training as part of an endpoint process, because it is more efficient to first Store the model and then Retrieve the model within a second process, the process that is actually exposed in the endpoint URL.
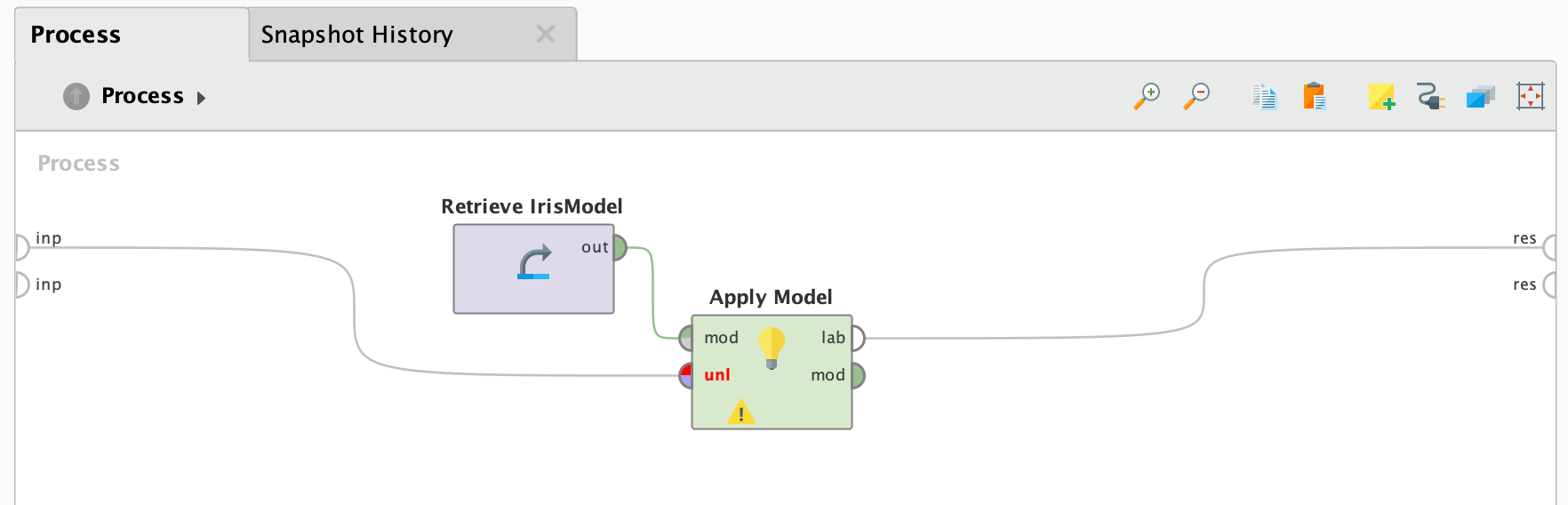
In our example, that second process is called ScoreIrisData; in this process
the Retrieve operator
loads the IrisModel that was created and stored in the first process.
The input data (and therefore the results) are lacking, but when we
request the results, we will POST our input data to the endpoint URL,
and in return we will get a prediction.
For easier local testing of this process you can take any of the following steps:
- drag and drop your test data on the input port,
- assign your test data to the input port via the context panel, or
- embed
ScoreIrisDatain an Execute Process operator, with your test data as input.
Within the context of RapidMiner Studio, your test data has RapidMiner's
standard data table format (.rmhdf5table), but in the context of endpoints,
you will POST your data in JSON format.
The Web API agent converts JSON to .rmhdftable before executing the process.
Note that In general, an endpoint can deliver any result that can be created by RapidMiner; it is not limited to processes that involve models and predictions.
Nevertheless, if your process involves long-running processes, such as model-building, you will be better served by the job execution infrastructure.
Next: Create an endpoint